A new preconditioned Richardson iterative method
Abstract.
This paper proposes a new iterative technique for solving a linear system based on the Richardson iterative method. Then using the Chebyshev polynomials, we modify the proposed method to accelerate the convergence rate. Also, we present the results of some numerical experiments that demonstrate the efficiency and effectiveness of the proposed methods compared to the existing, state-of-the-art methods.
Key words and phrases:
iterative method, Richardson iteration, convergence rate, Chebyshev polynomials.2005 Mathematics Subject Classification:
Primary 65F10; Secondary 65F08.1. Introduction and preliminaries
Linear systems arise in various scientific and engineering applications, including differential equations, signal processing, and optimization [4, 5, 6, 7, 8, 12]. Therefore, it is crucial to find the efficient solution of a linear system in both theoretical and practical contexts. Iterative methods of solving linear systems have been extensively studied because they are more efficient than direct methods when solving large-scale problems. Furthermore, iterative methods have the advantage of being easily adaptable to different types of linear operators, which makes them versatile and applicable to a broad range of problems. Such operators frequently arise in practical applications, including image processing and machine learning.
In the present work, we propose a new iterative method for solving linear systems with bounded, self-adjoint operators and then present a new, modified version of the process by using the Chebyshev polynomials. The method utilizes a flexible preconditioner that adapts to the structure of the operator and exploits its self-adjointness. The resulting algorithms have favorable convergence properties and require fewer iterations than some existing methods. Also, we present the results of some numerical experiments that demonstrate the efficiency and effectiveness of our methods compared to the existing, state-of-the-art methods.
Consider the linear system
| (1) |
in a Hilbert space , where is a bounded and self-adjoint operator. The basic idea of an iterative method is to use an initial guess , and then apply a sequence of updates to the solution, refining the solution with each iteration. There are many different iterative methods, each having its advantages and disadvantages, depending on the properties of the equation to be solved.
The most straightforward approach to an iterative solution is to rewrite (1) as a linear, fixed point iteration. If we consider the function on , then is a solution of if and only if is a fixed point of . Thus, it seems natural to consider fixed-point theorems.
One of the best and most widely used methods to do this is the Richardson iterative method [12]. The abstract Richardson iterative method has the form
| (2) |
where and is the residual vector . Note that we can rewrite (2) as
The Conjugate Gradient method is a more sophisticated method that uses information about the residual error to guide the iterative updates [12]. The update for the th iteration is given by
where is the step size, is the search direction given by
and
is the residual, with determined by the Conjugate Gradient method.
However, it is possible to precondition the linear equation (1) by multiplying both sides by an operator to obtain , so that the convergence of the iterative methods is improved. In this case, the residual better reflects the actual error. This method is a very effective technique for solving differential equations, integral equations, and related problems [2, 9, 10].
In general, iterative methods are powerful tools for solving large systems of linear equations. By choosing an appropriate iterative method based on the properties of the operator under consideration, it is possible to obtain fast and accurate solutions to a wide range of linear systems.
2. Preconditioning the problem based on Richardson’s method
Based on the properties of the operator in equation (1), positive constants and exist such that for each ,
| (3) |
Although the positive definiteness of is essential for methods such as conjugate gradient, our method can disregard this property. This is more evident in the Numerical results section.
It is not difficult to show that the optimal parameters and in equation (3) are equal to and , respectively. Considering the properties of matrix , there exist constants and that satisfy the aforementioned equation. It is not imperative to utilize the optimized coefficients within this context. Consequently, precise knowledge of the eigenvalues of the matrix is not mandatory; an approximation thereof is sufficient.
Now, based on the Richardson iterative method, we consider the iteration
| (4) |
In this case, the following lemma holds.
Lemma 1.
Let be a bounded and self-adjoint operator on a Hilbert space . Then
where and are the constants used in (3).
Proof.
Similarly, we can prove that for every ,
Therefore,
| (5) |
Finally, inequality (5) allows us to conclude that
which completes the proof. ∎
Note that the optimal convergence rate in the Richardson iterative method, obtained by letting , is .
In the following theorem, we show that the convergence rate of the iterative method (4) is .
Theorem 2.
Proof.
Note: Assume and . Let and , then and . Therefore, since , Lemma 1 and so Theorem 2 hold in this case.
To summarize the results obtained so far, we present an algorithm that generates an approximate solution to equation (1) with prescribed accuracy.
3. Modification by Chebyshev polynomials
In this section, the properties of the Chebyshev polynomials are used to modify the previous algorithm to accelerate the convergence rate.
Considering the iteration (3), let , where . In this case, based on the proof of the previous theorem,
By setting and , we see that
| (6) |
Since is invertible and self-adjoint, is a positive definite operator. Also, by the previous lemma, the spectrum of is a subset of the interval , where . Therefore, in view of (6), the spectral theorem leads to
| (7) | ||||
In the sequel, we aim to minimize . We have to find
| (8) |
where is a polynomial of degree with .
We investigate the solution to this problem in terms of the Chebyshev polynomials [3]. These polynomials are defined by
and satisfy the recurrence relations
The following lemma presents a minimization property of these polynomials which will be used later.
Lemma 3 ([3]).
Let and set
for . Then, for each ,
Furthermore,
This lemma shows that the minimization problem (8) can be solved by setting and . These lead to
| (9) |
which solves (8).
Now, we rewrite by using the Chebyshev polynomials. First of all, combining (9) with the definition of the Chebyshev polynomials (the recurrence relation) for , we obtain
Replacing with and applying the resulting operator identity to yield
By (6) and the fact that is the solution of the minimization problem (8), the above equation can be recovered as
or equivalently,
Repeated application of the recurrence relations of the Chebyshev polynomials for leads to
and hence
| (10) | ||||
If we set
then according to the properties of the Chebyshev polynomials we obtain
This yields
| (11) |
Also, a straightforward computation gives us the following recursive relation for ,
| (12) |
Now, based on the recursive relation (12), we design the following algorithm to approximately solve equation (1).
The following theorem investigates the convergence rate of the Algorithm.
Theorem 4.
If is the exact solution of (1), then the approximate solution given in Algorithm 2 satisfies
Also, the output of Algorithm 2 satisfies
Proof.
By definition of Chebyshev polynomials and with a few straightforward calculations, we obtain
Thus, by setting
we conclude that
Combining this equality with a relation (13), we obtain the desired result. ∎
It is expected that methods utilizing more spectral information to yield better results compared to those relying solely on matrix-vector products. However, the exact eigenvalues are not necessary for our method, as we assume that the coefficients and exist.
4. Numerical results
In this section, we present several examples to evaluate the efficiency and performance of our algorithms and compare them with several well-known algorithms in some cases. In addition, we compare our algorithms, namely, Algorithm 1 and Algorithm 2, with each other as well as with the Richardson and Conjugate Gradient (CG) algorithms in some cases.
The reported experiments were performed on a 64-bit 2.4 GHz system using MATLAB version 2010.
In the following two examples, we show the efficiency of our novel algorithms by using and systems, respectively. Both examples use the tolerance threshold .
Example 5.
Let
Since
it is straightforward to investigate that is invertible, self-adjoint and positive definite. Assuming
and concluding and , the following results are obtained for the system .
The exact solution for this system is
and as mentioned above, the given tolerance threshold is . First, we use Algorithm 1 to approximate the solution of this system. By using Algorithm 1, we obtain the approximate solution after iterations within Also, Algorithm 2 gives an approximation of the solution within after only iterations.
As discussed in Section 2, it is unnecessary to utilize the optimal values of and as the eigenvalues of the matrix ; a mere approximation is sufficient. Methods such as the Power Method [13] and the Jacobi Method [13] can be employed to approximate the eigenvalues of .
To demonstrate the efficacy of our algorithms with approximate values of and , we employed several approximated values for and in Example 5. The resulting data is summarized in Table 1. In this table, the first column corresponds to the optimal values of and , while the second and third columns represent the data corresponding to the approximate values.
| , | , | , | ||||
|---|---|---|---|---|---|---|
| Algorithm | ||||||
| Algorithm 1 | ||||||
| Algorithm 2 | ||||||
As shown in Table 1, the further we deviate from the optimal values and , the number of iterations increases in both our algorithms, but the computational error decreases due to the increased number of iterations. This demonstrates that our algorithms also perform well with approximate values for and .
Example 6.
Suppose that is the matrix
Then, similar to the previous example, we conclude that is self-adjoint, invertible and positive definite. Using approximations and of the exact optimal values for and , and if
then the exact solution of the system is
Applying Algorithm 1 with , the number of iterations required to converge to the system solution is within , while this number is equal to with for Algorithm 2.
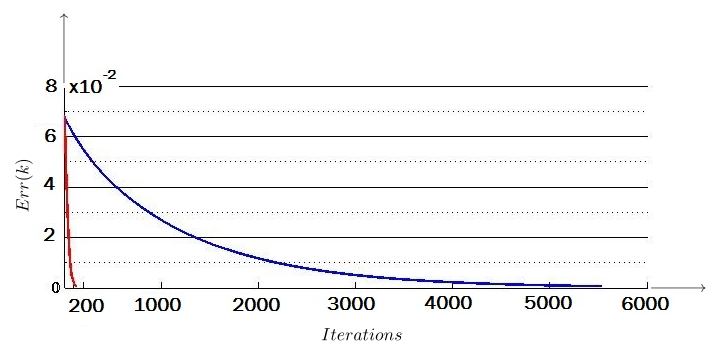
Here, the error function can be defined by at each step of the iterative method, where is the th approximation of the solution and is the exact solution of the system. We indicate the value of this function at the final iteration by . For the approximate solution obtained from Algorithm 1 in the previous example, this value is , which is a little less than that of Algorithm 2 with . Nevertheless, these error function values indicate that the final approximation obtained from each of our two algorithms is accurate up to four decimal places. Fig. 1 shows how Algorithm 1 and Algorithm 2 converge to the exact solution of the system in Example 6.
Although the Richardson iterative method is a light calculation method that is used in many applications of iterative methods in the solution of linear systems, our examples show that in many cases, the number of iterations required to reach the desired solution in Richardson’s method is greater than that of our second method. For instance, in the following example and the special case , the number of iterations required in Richardson’s method is equal to and the final error value is equal to . But, in our second algorithm, this number is equal to with an error value equal to .
Example 7.
Let
It is straightforward to investigate that is invertible and self-adjoint. Assuming
and , the following results are obtained for the system .
The maximum error for the approximate solution of this system is . For the case , Richardson’s method obtains the approximate solution after iterations with time and , but for Algorithm 2, these numbers are iterations with and . In this case, Algorithm 1 works slowly but finally converges to the exact solution of the system. Here, the CG method does not work at all.
The optimal values for and in the previous example are and . As can be seen, in this example, there is no need to use optimal values for and . Table 2 presents the numerical results of the iterations required to converge to the exact solution of the systems in Example 7.
| The Richardson algorithm | |||
|---|---|---|---|
| Algorithm 1 | |||
| Algorithm 2 | |||
| The CG algorithm | No Respond | No Respond | Not Respond |
As shown in Table 2, in this special example, the well-known method CG does not work at all, while our first algorithm works, although slowly!
Also, we can see in Table 2 that the required number of iterations with different values of in Algorithm 2 is less than that of Richardson’s method.
According to the above example, if we ignore the condition of positive definiteness, then the algorithm of the Conjugate Gradient method fails to work. Moreover, if the matrix of the system has negative eigenvalues, then the Richardson iterative method fails to work either. The following examples illustrate such systems.
| The Richardson algorithm | No Respond | No Respond | No Respond |
|---|---|---|---|
| Algorithm 1 | |||
| Algorithm 2 | |||
| The CG algorithm | No Respond | No Respond | No Respond |
| The Richardson algorithm | No Respond | No Respond | No Respond |
|---|---|---|---|
| Algorithm 1 | |||
| Algorithm 2 | |||
| The CG algorithm | No Respond | No Respond | No Respond |
Example 8.
Assume that
and
then the eigenvalues of are negative. Therefore the parameter in Richardson’s method is negative so it will not work for solving the system . But in this case, with and , both our two algorithms lead to the approximated solution for the system properly.
In addition, due to the non-definite positivity of , the CG method does not respond.
| Algorithms | Number of iterations | Run-time | |
|---|---|---|---|
| Algorithm 1 | |||
| Algorithm 2 |
| Algorithms | Number of iterations | Run-time | |
|---|---|---|---|
| Algorithm 1 | |||
| Algorithm 2 |
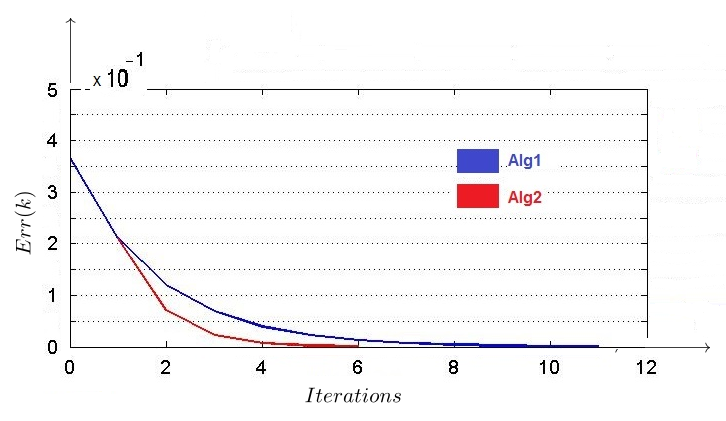
In Fig. 2, we show the way our algorithms converge to the exact solution during successive iterations. We use the broken-line diagram to compare the convergence of our algorithms at each step . As seen in Fig. 2, Algorithm 2 converges faster than Algorithm 1. Also, the CG algorithm operates at only one step and fails to converge. Note that this diagram corresponds to the error threshold .
Here is another example in which Richardson’s method fails to converge due to a negative parameter .
Example 9.
Suppose that in the linear system , the matrix of is given by
and
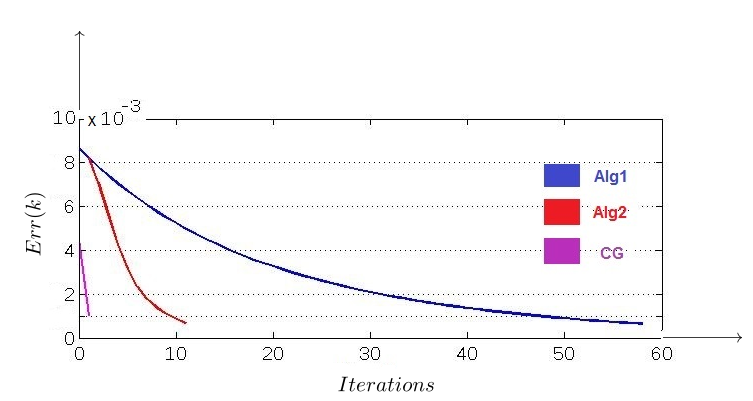
Then, and . So, and this means that the Richardson iterative method fails to converge in this case. The maximum error of the approximate solution is equal to the norm of the exact solution, which is . Let . Then, by using and , Algorithm 1 converges in steps with final error . Also, Algorithm 2 converges in steps, and its final error is . This value equals for the CG method, which is greater than the threshold . Thus, in this case, the CG method fails to converge and operates only one step. Fig. 3 compares the convergence speeds of our algorithms with each other and with the Conjugate Gradient method in this example.
To demonstrate that an approximation of the optimal values and suffices for both our algorithms, we have obtained approximated values for and in the two examples above applying eigenvalue approximation methods, particularly the Power Method [13]. We then re-executed Example 8 and Example 9 using these approximations with a tolerance of . The results are summarized in Table 5 for Example 8 and Table 6 for Example 9.
As illustrated in Table 5 and Table 6, our algorithms exhibit favorable performance when utilizing the approximate values of and .
Example 10.
Let be the following matrix,
that is a finite difference discretization of the Laplace PDE of dimension 150 [11], and . Then is self-adjoint and invertible but not positive definite, hence in this case CG method does not work at all. Since eigenvalues of are all negative, the Richardson method cannot be applied. But our first method converges in seconds at steps and our second algorithm converges to the solution of the system in just iterations within seconds with final error for . This final error for our first algorithm is .
Here, and are optimal values satisfying in equation (3).
5. Conclusions
In this paper, we proposed two new iterative methods for solving an operator equation , with being bounded, self-adjoint, and positive definite. Our first method used an iterative relation with a convergence rate equal to and the second method used the Chebyshev polynomials to accelerate the convergence rate of the first method.
Although the Richardson and Conjugate Gradient methods are among the most popular methods used in various applications, they are inefficient for a wide range of linear systems. Our algorithms worked decently well in such cases. Both the Richardson and Conjugate Gradient methods have limitations in their fields of application. For instance, Richardson’s algorithm is limited by the assumption that the parameter is positive, and so, fails to work if . Nevertheless, our algorithms worked properly in most of these cases. Meanwhile, our second iterative method needed fewer iterations than Richardson’s method to converge. Also, the positive definiteness of the operator is an essential condition for the CG method, and the method fails to respond if the system’s operator is not positive definite. However, our algorithms can converge if the operator is only invertible and self-adjoint.
Since iterative methods have various applications in other branches of science, conducting research on these methods and their development can greatly help other researchers in different scientific fields. We hope that this work will motivate researchers to develop such methods and help other researchers in the field of numerical solutions of linear systems.
References
- [1]
- [2] S.F. Ashby, T.A. Manteuffel and J.S. Otto, A comparison of adaptive Chebyshev and least squares polynomial preconditioning for Hermitian positive definite linear systems, SIAM J. Sci. Statist. Comput., 13 (1992), pp. 1–29. https://doi.org/10.1137/0913001
- [3] C.C. Cheny, Introduction to Approximation Theory, McGraw Hill, New York, 1996.
- [4] S. Dahlke, M. Fornasier and T. Raasch, Adaptive frame methods for elliptic operator equations, Advances in comp. Math., 27 (2007), pp. 27–63.
- [5] I. Daubechies, G. Teschke and L. Vese, Iteratively solving linear inverse problems under general convex constraints, Inverse Probl. Imaging, 1 (2007), pp. 29–46.
- [6] H. Jamali and M. Kolahdouz, Using frames in steepest descent-based iteration method for solving operator equations, Sahand Commun. Math. Anal., 18 (2021), pp. 97–109. https://doi.org/10.22130/scma.2020.123786.771
- [7] H. Jamali and M. Kolahdouz, Some iterative methods for solving operator equations by using fusion frames, Filomat, 36 (2022), pp. 1955–1965. https://doi.org/10.2298/fil2206955j
- [8] H. Jamali and R. Pourkani, Using frames in GMRES-based iteration method for solving operator equations, JMMRC, 13(2023) no.2, pp. 107–119.
- [9] C.T. Kelley, A fast multilevel algorithm for integral equations, SIAM J. Numer. Anal., 32 (1995), pp. 501–513.
- [10] C.T. Kelley and E.W. Sachs, Multilevel algorithms for constrained compact fixed point problems, SIAM J. Sci. Comput., 15 (1994), pp. 645–667. https://doi.org/10.1137/0915042
- [11] R.J. LeVeque, Finite Difference Methods for Ordinary and Partial Differential Equations: Steady-State and Time-Dependent Problems, SIAM, 2007.
- [12] Y. Saad, Iterative methods for Sparse Linear Systems, PWS press, New York, 2000.
- [13] Y. Saad, Iterative methods for Sparse Linear Systems(2nd ed.), SIAM, 2011.
- [14]







